【多图长文预警,建议先码】在浏览器地址栏输入 URL 到页面渲染之间都经历了什么?这是一道很经典的问题,可以很全面的考验面试者对于网络知识的理解。这之间的过程是一环套一环,下面笔者通过这题来科普一下基础的网络知识。
太长不看简易版
- 用户在浏览器输入 URL
- 浏览器尝试读取 URL 的缓存
- 无缓存则开始查 URL 域名的 ip,也就是 DNS 查找
- 开始建立 TCP 链接,经过三次握手成功建立连接
- 客户端开始发送数据
- 服务端将用户所需的资源返回给客户端
- 若返回的是 HTML 文档的话,浏览器开始解析 HTML 文档
- 构建 DOM 树、构建 CSSOM 树
- 将解析步骤中创建的 CSSOM 树和 DOM 树合成为 Render 树,然后用于计算每个可见元素的布局,最后将其绘制到屏幕上
目录
地址栏
当我们在浏览器地址栏输入信息时,浏览器就已经开始进行工作了。首先它会监听我们输入的信息并尝试匹配出你想要访问的网址或关键词,以 chrome 为例,它会猜我们想要什么,给出下面的建议项:
- 使用默认搜索引擎搜索关键字
- 书签,历史记录和最近下载中存储的其他链接
- 使用默认搜索引擎的相关关键字搜索选项
我们在地址栏输入知乎首页的链接 zhihu.com 后敲下回车,命令浏览器搜索信息。接着大致会对输入的信息进行以下判断:
- 看看输入的是不是一个合法的
URL链接。 - 若是则判断输入的 URL 是否完整。不完整的话,浏览器可能会对域猜测,也就是说尝试通过在输入的内容中添加前缀、后缀或两者来 “补全”
URL。比如输入zhihu.com则可能会在前面添加www。 - 否,那就将输入的内容作为搜索的条件,使用用户设置的默认搜索引擎来进行搜索

浏览器根据我们输入的信息判断出 zhihu.com 是一个合法 URL,并被补全为 www.zhihu.com。
本章参考资料:
URL
经常上网的朋友经常能听说 URL 这个名词,那么它具体是干嘛用的呢?
URL 全称为**统一资源定位系统(uniform resource locator)**,用于表示一个因特网(Internet)上标准的资源的地址。就像每户人家都会有个门牌地址一样。维基百科对 URL 的术语上是这样解释:
每个 HTTP URL 都符合通用 URI 的语法(关于 URL 与 URI 的差别参请看下文的列参考资料)。URI 一般语法由五个的分层序列的组分:
1 | URI = scheme:[//authority]path[?query][#fragment] |
权限组件 (authority) 又分为三个子组件:
1 | authority = [userinfo@]host[:port] |
它在语法图表示为:

从术语上看好像有点抽象?没有关系,我们通过浏览器内部提供的 location 的接口来辅助理解,该接口表示其链接到的对象的位置(URL)。
我们另开一个标签页,随便打开一个较为复杂的 URL,如:
1 | https://github.com/anran758/Front-End-Lab/tree/master/css?name=anran758&uid=234098&shareId=456#layout |
接着在控制台的 Console 面板中直接输入 location 并敲下回车,它会输出一个对象,该对象内包含当前页面上的 URL 信息。
1 | { |
我们拿这个对象与 URL 的属于一一对应,就可以清晰看出他们之间的对应关系:
| URL 术语 | location 对象的 key | 匹配项 |
|---|---|---|
| scheme | protocol | https |
| host | hostname | github.com |
| path | pathname | /anran758/Front-End-Lab/tree/master/css |
| query | search | ?name=anran758&uid=234098&shareId=456 |
| fragment | hash | #layout |
scheme(方案),多时候情况下也称为protocol(协议),尾部跟随一个:作为分隔host(主机名), 它可以是一个 IP 或是一个域名(下文会讲解两者的概念)path(路径),以/区别每一层目录结构的名称。query(查询),以?为起点,以&分隔键值。
在上例中name就是键,anran758就是值。在页面上,前端可以通过URL来传递参数;在接口上,后端可以根据GET请求取得对应查询条件fragment(片段),以#为起点的部分。我们通常称这部分为哈希,它在浏览器上有特殊的作用。
如果页面上存在一个id=layout的元素,那么页面就会滚动到该元素之上。就像我们打开上面给出的示例URL后,页面加载后自动滚动在标题为layout上。
以上是我们在地址栏中常见的 URL(URI) 格式,但不够全面。比方说我们带上端口后,直接访问 https://github.com:443 会发现地址栏上并没有显示出端口号,这是为什么呢?
这是因为如果我们访问的 URL 使用的是以 https 开头的协议,那么 HTTPS 协议的默认的端口就是 443。即便我们特意补全这个端口号,浏览器还是默认会将该端口隐去。
同理,我们访问的是 http 协议,他的默认端口是 80 端口,也会自动隐藏掉。只有当我们访问与该协议默认端口不一致时,浏览器才会显示出来。比如 http://localhost:8000/analysis/project 就能看到它能在地址栏上正确的显示出来(笔者这里是以 chrome 浏览器为例,不同浏览器可能有不同的行为)。
完整的 URL 例子可以参见维基百科给出的示例:
1 | userinfo host port |
接着浏览器分析 URL 信息后,会从 URL 取出方案(协议类型)。这个方案可以是常见的 http:,也可以像 chrome 内置协议 chrome:。再根据不同的协议进行不同的解析。
我们在地址栏上输入的是 zhihu.com,没有指定要使用哪个协议,那这个这个判断的权利交给了浏览器,浏览器通过内置的方案来决定对 URL 信息进行补全。比如 chrome 可能会对该链接补全为 https://www.zhihu.com。
接着浏览器从 URL 中提取出主机名(host)信息。它可能是一个 IP 地址,也可以可能是一个域名地址。
1 | host port |
下面来了解一下关于 IP 地址和域名这两个概念。
本章参考资料:
IP 地址
因特网(Internet)就像个学校,每个资源都有自己的座位。当你获取某个资源时,首先需要确定资源的所在地,就像你要去别人家取货那起码得知道人家的地址。
IP 地址(Internet Protocol Address) 就是用于标识网络上设备的数据标签,也可以通俗的理解为住宅门牌号。它主要有 IPv4、IPv6 两个版本。
IPv4
IPv4 使用 32 位地址, 地址空间为 4,294,967,296(2^32)。它有 3 种常见的标记法,即:二进制标记法、点分十进制标记法、十六进制标记法,其中最常采用的标记法是方便人们记忆的点分十进制。以下是三者之间的比较:
| IPv4 标记法 | 表示方式 |
|---|---|
| 二进制 | 11000000 10101000 00000001 00000001 |
| 点分十进制 | 192.168.1.1 |
| 十六进制 | 0xC0A80101 |
IPv4 早已在我们身边普及。比方说我们需要重设 WIFI 密码,那得要登录路由器厂商提供的路由器管理后台(Admin),这个管理后台的登录地址通常是厂商默认设置的本地 IP 地址,如 192.168.1.1。
在 IPv4 的原始设计中,IP 地址分为两部分,分别是 8 位网络地址和 24 位主机位。因为局域网早期出现时,只有一些又大又少的网络。这种结构最多允许有 256 个网络,很快就发现这种结构完全不够用。
分类网络
为了克服这个限制,1981 年的 RFC 791 对 IP 地址定义进行了修改,定义了分类地址结构。修订后系统定义了五个类,分别是 A、B、C、D、E 五类。以下是分类地址结构的 IPv4 地址空间划分表:
| 类 | 地址范围 | 高序位 | 用途 | 百分比 | 网络地址位数 | 主机位数 | 网络数 | 每个网络的主机数 |
|---|---|---|---|---|---|---|---|---|
| A | 0.0.0.0 ~ 127.255.255.255 | 0 | 单播/特殊 | 1/2(128/256) | 8 | 24 | 128 | 16,777,216 |
| B | 128.0.0.0 ~ 191.255.255.255 | 10 | 单播/特殊 | 1/4 | 16 | 16 | 16384 | 65,536 |
| C | 192.0.0.0 ~ 223.255.255.255 | 110 | 单播/特殊 | 1/8 | 24 | 8 | 2,097,152 | 256 |
| D | 224.0.0.0 ~ 239.255.255.255 | 1110 | 组播 | 1/16 | N/A | N/A | N/A | N/A |
| E | 240.0.0.0 ~ 255.255.255.255 | 11110 | 保留 | 1/16 | N/A | N/A | N/A | N/A |
我们从表中可以得知,A、B、C 类用于为因特网(单播地址)中的接口分配地址,还有一些在特殊情况下使用不被分配的 IP。
单播和组播的概念很好理解。单播是指客户端与服务器之间的点到点连接。就像你跟小姐姐聊天是一对一之间的交流。
组播则是指在发送和接收者实现点对多点连接。下面二狗子的表情包很精准的阐述出组播的概念:
二狗子突然站起来对圈子(组播组)里的其他朋友说:”大家听我说,我发现我们都是狗!!”。二狗子发出了一条消息,组播组内的其他狗子同时接收到了这条消息。

使用分类地址划分后,不同类地址可以拥有不同规模的网络数和主机数。比如,A 类地址仅能分配 128 个网络给不同站点用,但一个网络内分配给 16,777,216(2^24) 台主机使用。而 C 类地址虽然能分配 2,097,152(2^21) 个网络,但每个网络只能容纳 256 台主机。这样就可以预先估计规模大小,然后再申请分类分配网络号,解决了早期不够用的问题。
其他分配方案
随着互联网发展,分类网络的形式使得很多地址空间没有被合理的利用上,C 类地址不足以承载太大的网站,进而去申请 B 类地址。导致 B 类地址迅速减少。IP 地址不够用的情况又出现了。为了解决这些情况,RFC 在基于 IPv4 地址上提出了以下的方案:
1985 年,随着 RFC 950 的发布,开始将现有的分类网络划分为子网。随后在 1987 年发布的 RFC 1109 中引入可变长度子网掩码(VLSM),该划分变得更加灵活。
1993 年,基于可变长度子网掩码 RFC 1517 引入了无类域间路由(CIDR), 正式地取代了分类网络,分类网络也因此被称为“有类别”的。
CIDR 被设计为可以重新划分地址空间,因此小的或大的地址块均可以分配给用户。CIDR 创建的分层架构由互联网号码分配局(IANA)和区域互联网注册管理机构(RIR)进行管理,每个 RIR 均维护着一个公共的 WHOIS 数据库,以此提供 IP 地址分配的详情。
– 以上 IPv4 地址方案发展历史截取至维基百科
IPv6
虽然通过以上几种 IPv4 地址分配方案缓解地址耗盡的问题,但还是治标不治本。为了彻底解决 IPv4 地址耗盡的问题,1998 年对使用 128 位 IP 地址的 IP(IPv6)新版本进行了标准化。
IPv6 地址的出现不仅解决了 IPv4 地址空间不够的问题,还实现了 IPv4 中不存在的功能。
在 IPv6 中,地址大小从 IPv4 中的 32 位增加到 128 位,从而提供了多达 2128 个(大约 3.403 × 10^38)地址。这个数字什么概念呢?我们以维基百科统计的世界人口来对比。截止至 2019.05,世界人口约为 77 亿人(7.7 × 10^9)。因此在可预见的未来里,这被认为是够用了的。
IPv6 地址为 128 位元长,但通常写作 8 组,每组 4 个十六进制数的形式。如果四个数字都是 0,可以被省略。例如:
1 | 2001:0db8:85a3:0000:1319:8a2e:0370:7344 |
为避免 IPv6 地址的冒号与方案的冒号冲突,在 IPv6 地址在 URL 上是通过中括号包裹,以百度的 IPv6 地址为例:
1 | http://[2400:da00:2::29]/ |
目前我们见到更多的是 IPv4 地址。IPv6 是未来的主流,目前仍然在部署中。国内的部署情况可以在百度百科《IPv6》的发展历史中能找到相关的描述:
2018 年 6 月,三大运营商联合阿里云宣布,将全面对外提供 IPv6 服务,并计划在 2025 年前助推中国互联网真正实现“IPv6 Only” 。
7 月,百度云制定了中国的 IPv6 改造方案。
8 月 3 日,工信部通信司在北京召开 IPv6 规模部署及专项督查工作全国电视电话会议,中国将分阶段有序推进规模建设 IPv6 网络,实现下一代互联网在经济社会各领域深度融合。
11 月,国家下一代互联网产业技术创新战略联盟在北京发布了中国首份 IPv6 业务用户体验监测报告显示,移动宽带 IPv6 普及率为 6.16%,IPv6 覆盖用户数为 7017 万户,IPv6 活跃用户数仅有 718 万户,与国家规划部署的目标还有较大距离。2019 年 4 月 16 日,工业和信息化部发布《关于开展 2019 年 IPv6 网络就绪专项行动的通知》。5 月,中国工信部称计划于 2019 年末,完成 13 个互联网骨干直联点 IPv6 的改造。
好啦,关于 IP 地址的基础概念就讲到这里。关于 IP 地址更深入的知识可以去找相关的专业教材或书籍,本文将不过多赘述。
本章参考资料:
域名系统(DNS)
理论上我们直接使用 IP 地址就可以访问资源了。但直接通过 IP 地址来访问会存在一个问题,那就是 IP 地址不便于人类记忆。考虑以下场景对话:
“嘿朋友。最近我做了个主页,有空来我留言板踩踩呗?”,”没问题呀,那么地址是什么呢?”。(以下弹出一个选项框)
1 | 选项A: http://[2400:da00:2::29]/ |
将上面三个选项进行对比就能发现:如果我们十分硬核的选择了 A、B 两项,那你的朋友可能会给你翻个白眼。这样的地址谁想记呀!!即便是朋友愿意记下你的 IP 地址,但把该网站的定位转为商业网站后,显然这就有点为难用户了。
tips: 在命令行使用
nslookup baidu.com可以获得百度的 ip 地址
因此,为了克服 IP 地址不便于人类记忆和理解的情况,人们设计出域名来辅助记忆。
域名(Domain) 在术语上定义,是由一串用点分隔的字符组成的互联网上某一台计算机或计算机组的名称,用于在数据传输时标识计算机的电子方位。它有一定的自然语言含义。所以它相当于是 IP 地址的一个映射。
你不是 IP 地址记不住吗?那我把 IP 地址映射为人们熟知的拼音语句、英语单词等常见词语。183.232.231.174 我可以映射为 taobao.com 、 baidu.com 、12306.cn。这样是不是好记多了?
确实,IP 地址被映射为域名后,人们记域名方便方便多了。但问题又来了,底层计算机并不认识域名这种东西、它寻址还是得通过 IP 地址来寻址。发起请求时需要有应用告诉计算机这个域名的 IP 地址是什么。
DNS
域名系统(Domain Name System, 下文统一简称为 DNS) 的任务就是负责将域名解析为 IP 地址。这个解析的过程也被称为 **名称解析(name resulution)**。
DNS 是互联网上重要的基础应用程序,它作为一个分布式数据库,域名服务器分布在世界各地,储存着域名与 IP 地址的映射关系,每个域名服务器上值存储了部分域名信息。因此为了完成域名解析,通过需要在多个域名服务器之间进行查询。
DNS 为了实现域名的有效管理与高效的查询,它是按层级结构进行组织的,并且该层次结构与域名的结构( . 分隔)相对应,每个以点分隔的为 标签(label)。它所使用的所有名称集合构成了 DNS **名称空间(name space)**。
当前的名称空间是一棵域名树结构,位于顶部的树根(root, 通常为我们称之为根域名服务器)为命名。树第一层为**顶级域名(Top level Domian, TDL)**,TDL 再往下就是子域名。域名的层级是从右往左看:
1 | 三级域名.二级域名.顶级域名.根域名 |
因此 www.zhihu.com 完整的域名应该是 www.zhihu.com.。后面的 . 相当于 .root,由于每个域名的根节点都是 root,因此 .root 就被省略为 .。我们直接访问 zhihu.com. 是能正确的打开知乎首页的。
一个服务器所管辖的范围叫做区(zone)。每一个区设置相应的权威域名服务器,用于保存该区中所有的主域名到 IP 地址的映射。其中 DNS 服务器的管辖范围不是以 “域” 为单位,而是以 “区” 为单位。域名服务器根据其主要保存的域名信息以及在域名解析过程中的作用等,可以分为根域名服务器、顶级域名服务器、权威域名服务器。
根域名服务器是最重要的域名服务器,因为所有域名解析操作均离不开它们。在因特网上指定了 13 个逻辑根名称服务器,逻辑名称的格式为字母 .root-servers.net,字母范围从 a 到 m。如: a.root-servers.net、d.root-servers.net 等。
顶级域名服务器负责管理在该顶级域名服务器注册的所有二级域名。顶级域名服务器的名称对应着域名的最后一个名称。如 www.zhihu.com 的顶级域名服务器名称是 com。
权威域名服务器,负责一个区的域名服务器,保存该区中的所有主机的域名到 IP 地址的映射。任何一个拥有域名的主机,其域名与 IP 地址的映射关系等信息都存储在所在网络的权威域名服务器上。在进行域名解析时,只要找到被查询域名主机注册的权威域名服务器,就可以获得该域名对应的 IP 地址信息。
本地 DNS
任何一台主机(PC、手机等)在网络地址配置时,都会配置一个 DNS 服务器作为默认域名服务器,这样这台主机在任何时候需要进行域名解析,都会将域名查询发送给该服务器,这个默认服务器我们称之为本地域名服务器。在 MacOS 环境下可以输入以下命令来查看 DNS 的配置:
1 | ➜ blog git:(master) ✗ scutil --dns |
从缓存的角度来看,有分 DNS 服务器缓存和应用级 DNS 缓存。
浏览器向 DNS 服务器发起请求,DNS 会从自己的缓存中读取记录,如没有结果才向上一层请求,这是属于应用级缓存。chrome 早期可以通过访问 chrome://net-internals/#dns 来查看浏览器缓存的 DNS 记录,但不知什么原因现在把查看 DNS 信息的页面给砍掉了,只留清除 DNS 缓存的功能。而 Firefox 可以直接访问 about:networking#dns 查看对应的域名映射。
hosts
除了 DNS 服务器与 DNS 缓存外,其实还有一种途径能读取域名映射,那就是 hosts 文件。
hosts 文件是纯文本文件。从历史的角度看,hosts 文件出现的比 DNS 服务器还早。最初在 Internet 的前身 ARPANET 中,其成员 SRI International 手动维护并分享的一个名为 HOSTS.TXT 的文件。它负责将主机名称映射到相应的 IP 地址。
由于个人网络不断庞大之后,对 hosts 文件进行管理的难度也越来越大,于是在 1983 年 DNS 系统开始开发,1984 年得到了发展。并且随着网络的发展,DNS 可以自动提供动态的主机名解析,因此 hosts 成为了一个可以作为备用手段的名称解析机制。
与 DNS 不同的是,hosts 文件是可以由用户改写的,是属于操作系统级别的 IP 地址映射。同时在一些操作系统上,hosts 文件可能会比其他域名解析器(如 DNS 服务器)会具有更高的优先级。
hosts 文件在不同操作系统下路径是不一样的。以下给出常见的操作系统路径:
1 | # win7 +, %SystemRoot%\ 系统根路径默认为 c 盘,也就是 c:\ |
hosts 文件内容由第一行文本字段中的 IP 地址和一个或多个主机名组成的文本行。每个字段都用空格隔开(出于历史原因,通常首选使用 Linux 上的 hosts 直接复制到 window 上可能不会生效)。井号(#) 后文字为注释信息,文件中的完全空白行将被忽略。典型的主机文件可能包含以下内容:
1 | 127.0.0.1 localhost |
除此之外,hosts 文件还可以做其他用途。
比如原本我们开发环境的 URL 可能是 192.168.6.106:8000, 现在页面上有一个强依赖于当前 URL 域名的功能或校验。但我们得要完成测试开发,这怎么办呢?总不能先部署上线再测试吧,这多麻烦呀..
这里就可以通过修改本地的 hosts 文件,将 192.168.6.106 映射 www.example.com,然后我们直接访问 www.example.com:8000 进行测试即可。
再比如,我们浏览器可能会装有广告拦截插件,但总有一些漏网之鱼怎么办?没有关系,我们直接在浏览器控制台打开 Network, 找到广告的地址,将该域名映射为本地专用网络 127.0.0.1 上。那该页面发起的广告请求将不能正常的获取到资源,也是一种屏蔽广告的好方法。
可以做一个简单的测试。打开 hosts 文件,修改以下映射(需要管理员权限),再打开匿名模式访问百度首页,然后会发现浏览器提示: 无法访问此网站 baidu.com 拒绝了我们的连接请求。
1 | 127.0.0.1 localhost baidu.com |
修改 hosts 文件能我们提供一些便利,但同时也要防止有人恶意篡改我们的 hosts 文件(通过病毒等途径),引导至诈骗网站。
hosts 文件是系统文件,直接通过路径找 hosts 文件对于一些朋友来说感觉会有点繁琐。因此在不同操作系统下有开发者开发了这方面的便捷工具,如 MacOS 上可以下载 SwitchHosts 来辅助修改,也可以在其官网上查看它提供了哪些功能。
域名解析
现在我们回归主线,对以上本地 DNS 解析的优先级做一个梳理:
在地址栏输入 URL 的主机名是域名的话,那么浏览器将会调用域名解析器。这个域名解析器的优先级可能根据操作系统的不同会有所差异:
1 | 浏览器 DNS 缓存 > hosts 文件(或 hosts 文件 > 浏览器 DNS 缓存) > 本地 DNS 服务器 > ISP(因特网提供商) DNS 服务器 |
现在我们假设浏览器缓存会被最先查找,正式来了解域名解析的过程:
一、 首先浏览器从 URL 提取出主机名,从浏览器 DNS 缓存中查找是否有对应的记录。
二、 应用缓存中没有找到记录的话,会进一步查找 hosts 文件是否有记录映射关系,有则停止下一步查找,并返回结果。
三、 如果前两步骤都没有找到对应的映射地址的话,将会向本地 DNS 服务器发送请求。以下对本步骤进行详细讲解:
要了解 DNS 查询细节的话,那得先学习一下 DNS 的信息格式,然后我们可以安装 Wireshark 捕获请求分组来辅助学习:

安装该软件后,点击开始捕获分组并在过滤器上输入 dns 后敲回车。接着在浏览器上访问 zhihu.com 捕获到如下数据:
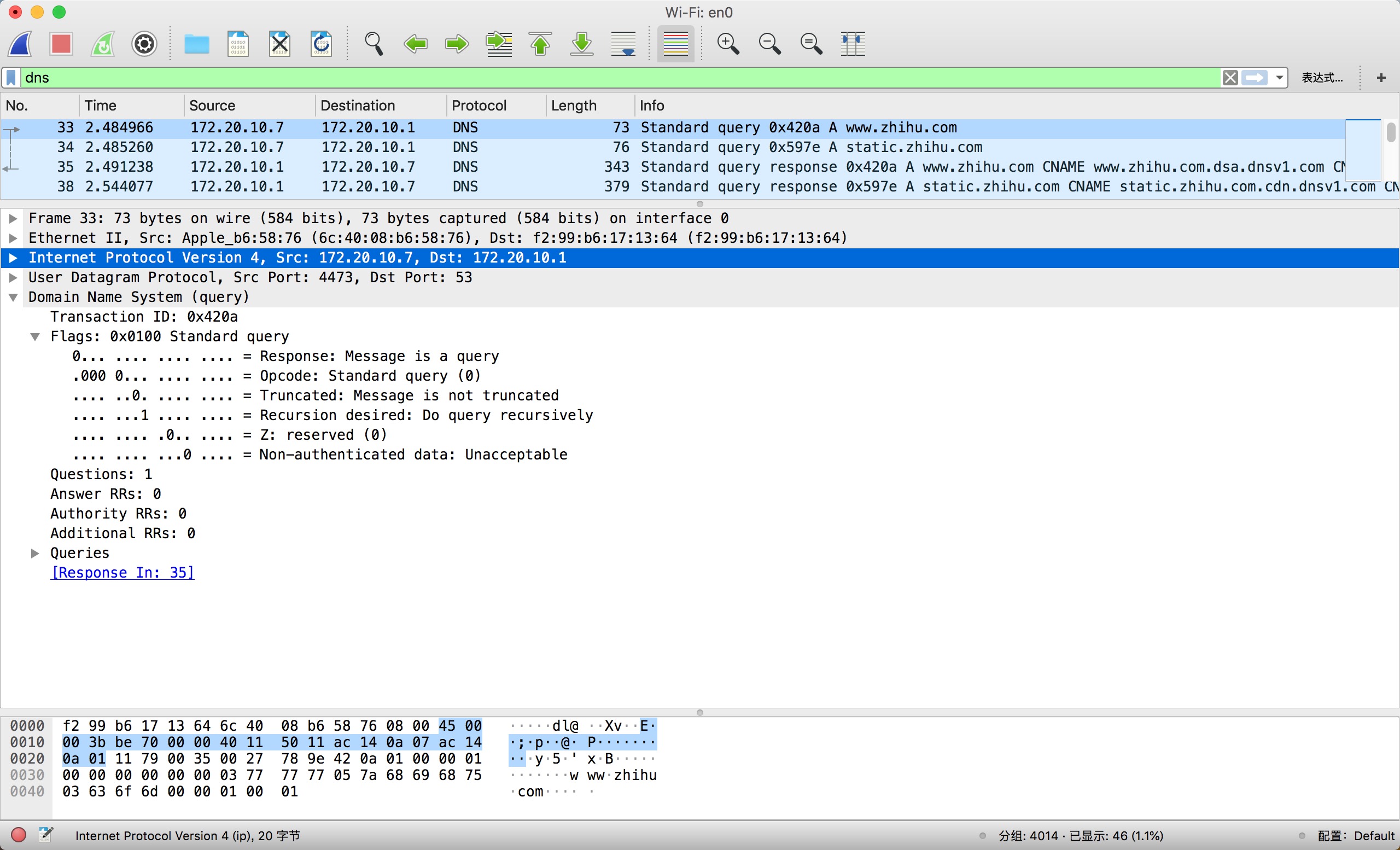
从上图选中数据报的头部可以看出,这是是一个 UDP/IPv4 数据报,同时数据报带有 DNS 头部信息。
这是一个标准的 DNS 查询,发送端 IP 地址是 172.20.10.7, 端口号为临时分配的 49246。这个数据报发往本地 DNS 服务器 172.20.10.1,端口号为知名 DNS 端口 53.
把 DNS 头部信息与 DNS message 格式进行对比就能得知,Transaction ID 就是 占 16 个比特位(以下单位简称为位)的 ID,其值为 0x420a。
flags 的标记可以得知该 DNS 消息的状态与类型。flags 占 16 位,是标志(或者说属性)的集合,总共有十个标记。下面再补上 DNS 响应来一并讲解 flags:
Tips: DNS 协议分请求报文和响应报文。在面板上的
No.一栏中两个箭头代表着查询发出与响应返回,具有对应关系。
在 Wireshark 面板下,Flags 内每一行代表着一个属性说明,看上去还是挺工整的。
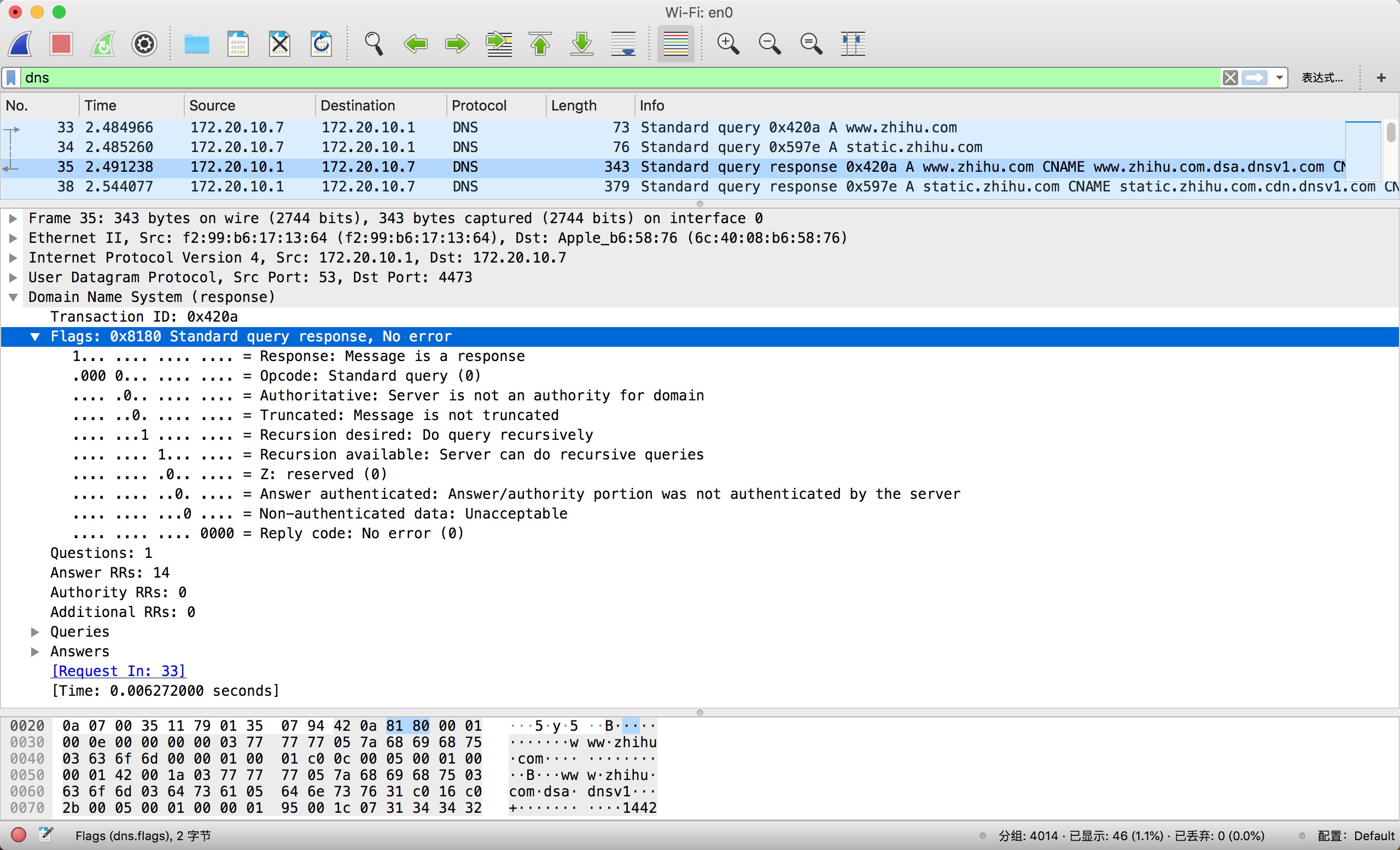
- 第一个标志
QR(Query / Response)占 1 个位,代表本条消息是查询(query, 0), 还是响应(response, 1)。 - 第二个标志是操作码(
OpCode)占 4 位。不管是响应和查询,全零都代表是标准查询。 - 第三个标志
AA(Authoritative Answer)占 1 位,代表着授权回答。这个标志在上图的查询中没有显示出来是因为该标志只对响应有用。 - 第四个标志
TC(TrunCation)占 1 位,代表该消息是不是“可截断的”。1代表可截断,0为不可截断。 - 第五个标志位
RD(Recursion desired)表示“期望递归”,占 1 位,它告诉服务器执行递归执行。图中查询和响应的标志位被设为1, 意味着以递归方式进行查询。 - 第六个标志位
RA(Recursion available)占 1 位,如果服务器支持递归查询,将会在响应中设置该标志。本地 DNS 服务器一般是使用迭代方式进行查询,而根服务器仅支持迭代查询。 - 第七个标志位
Z占 1 个比特位,该标志是保留字段,以供未来使用。 - 第八个标志位
AD(Answer authenticated)占 1 位。如果包含的消息已授权,则该标志位会被设为1。如果禁用安全检查,则下一个标志位CD会被设置为1. - 第九个标志位
CD(Checking Disabled)占 1 位,该指示发送查询的解析器是否可以接受未经身份验证的数据。设置1为禁用安全检查接受未经身份验证的数据,设置0则不接受未经验证的数据, - 第十个标志位
RCODE(Response Code)占 4 位,表示响应的状态码,全零意味着没有错误(Not Error)。
除了 flags 外,下面还有请求数(Questions)、回答记录数(DNS 消息格式示意图中的 ANCOUNT,Wireshark 上的 Answer RRs。其中 RRs 全称为 Resource Records,也就是资源记录)、授权记录数(Authority RRs)、其他额外信息数(Additional RRs),这些都是字面意思,不过多解释。
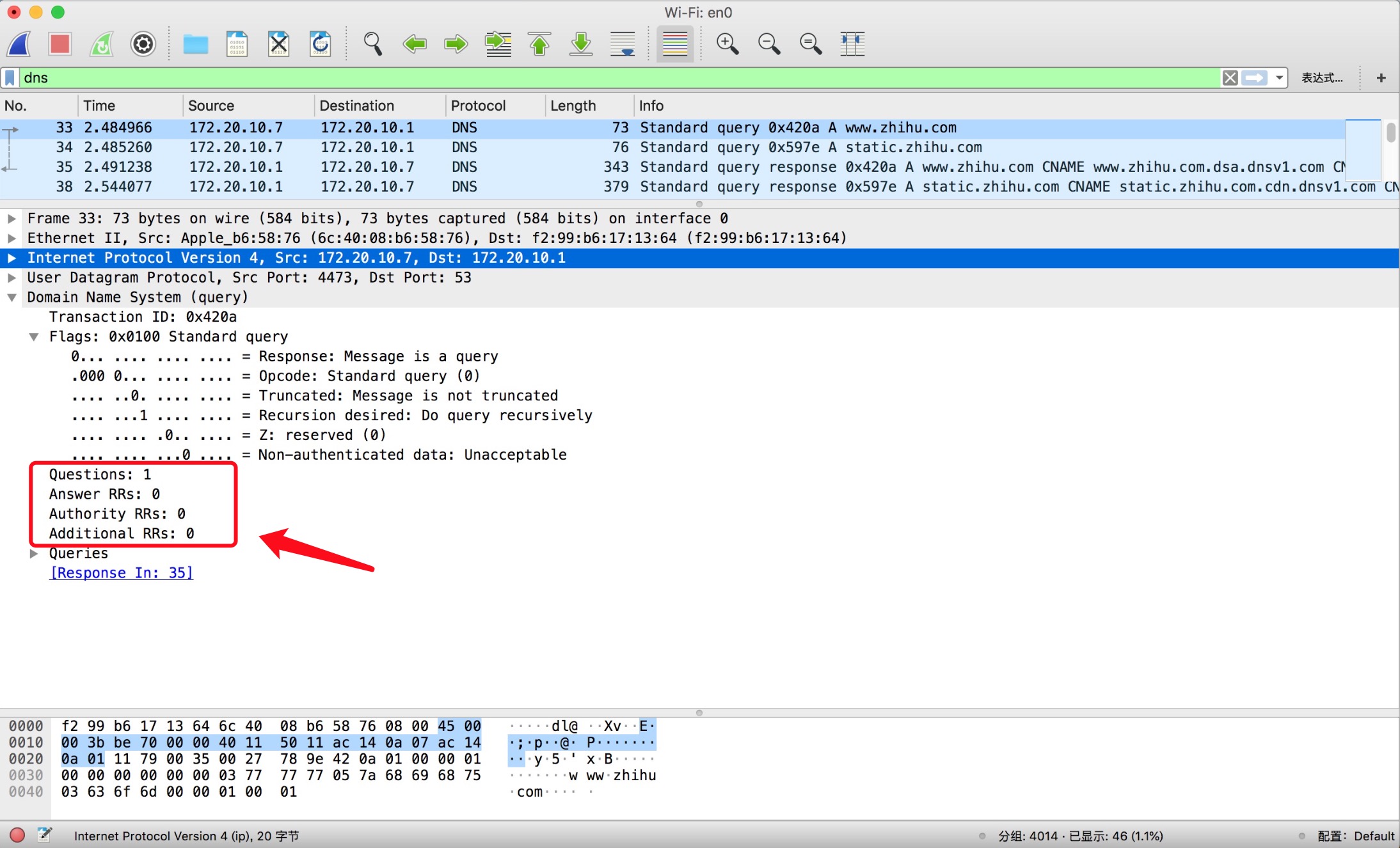
在查询与响应中,我们可以看到有相同的 Queries,Queries 中有一个询问(Querie)。对于 DNS 查询意味着 DNS 客户端问 DNS 服务端问题,期望从它那边得到 www.zhihu.com 的 IP 地址。要求去 IN(互联网) 类中找到 A 类型(IPv4 地址记录) 的信息。对于 DNS 响应来说,这只是从查询那里拷贝过来的副本。
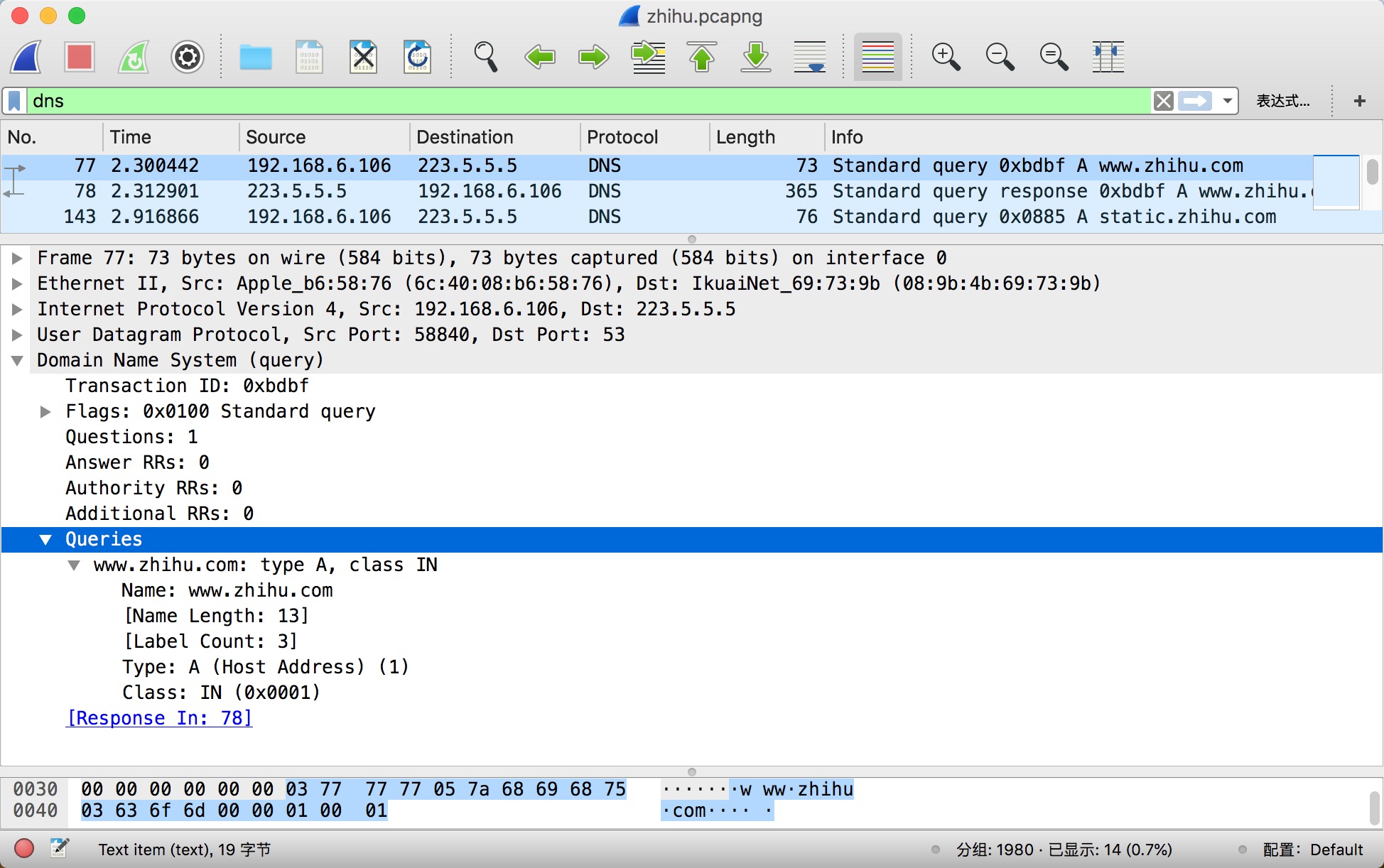
关于 class 可以在下表中找到对应的含义。type 类型略庞大,笔者仅从维基百科截取其中一部分:
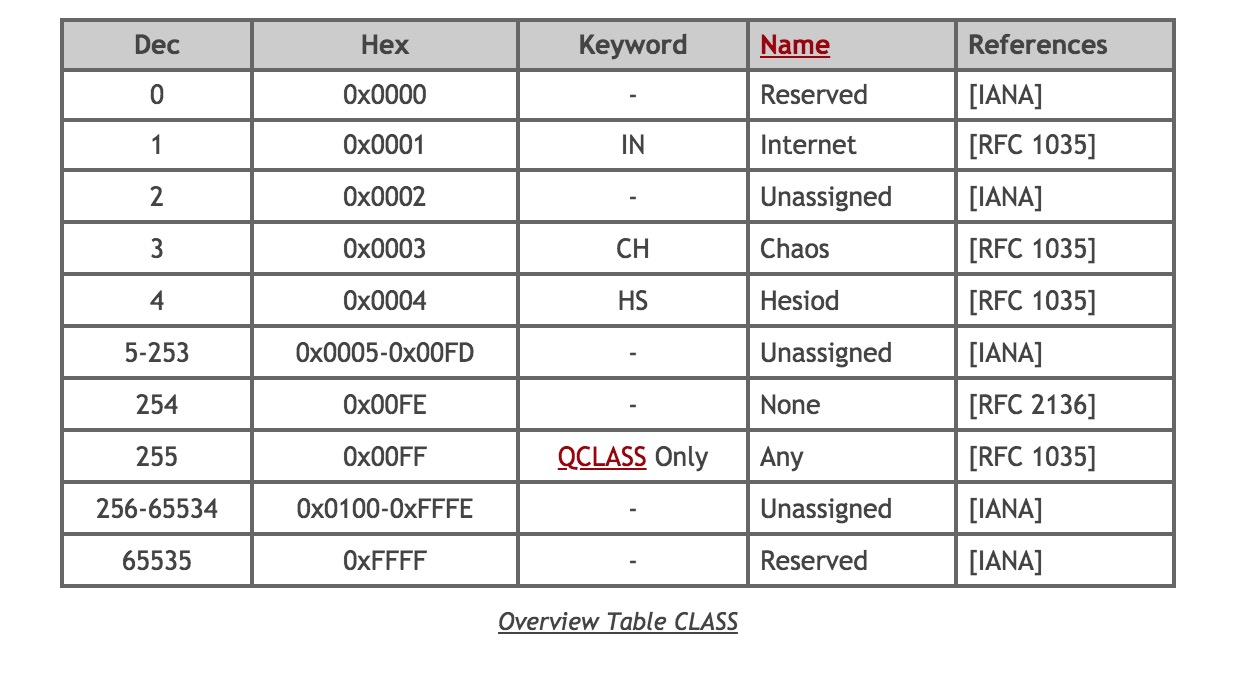
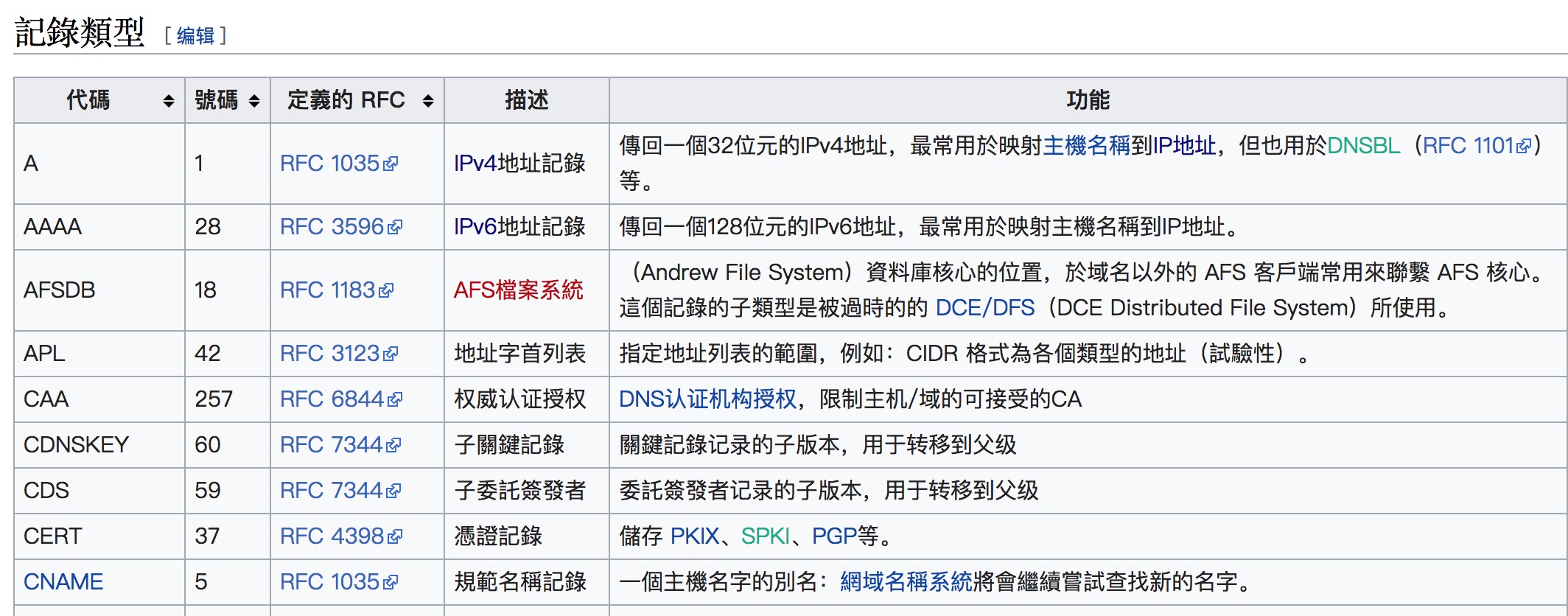
DNS 响应中还会有 Answers 这个属性,代表着它对 Queries 给出的答案:
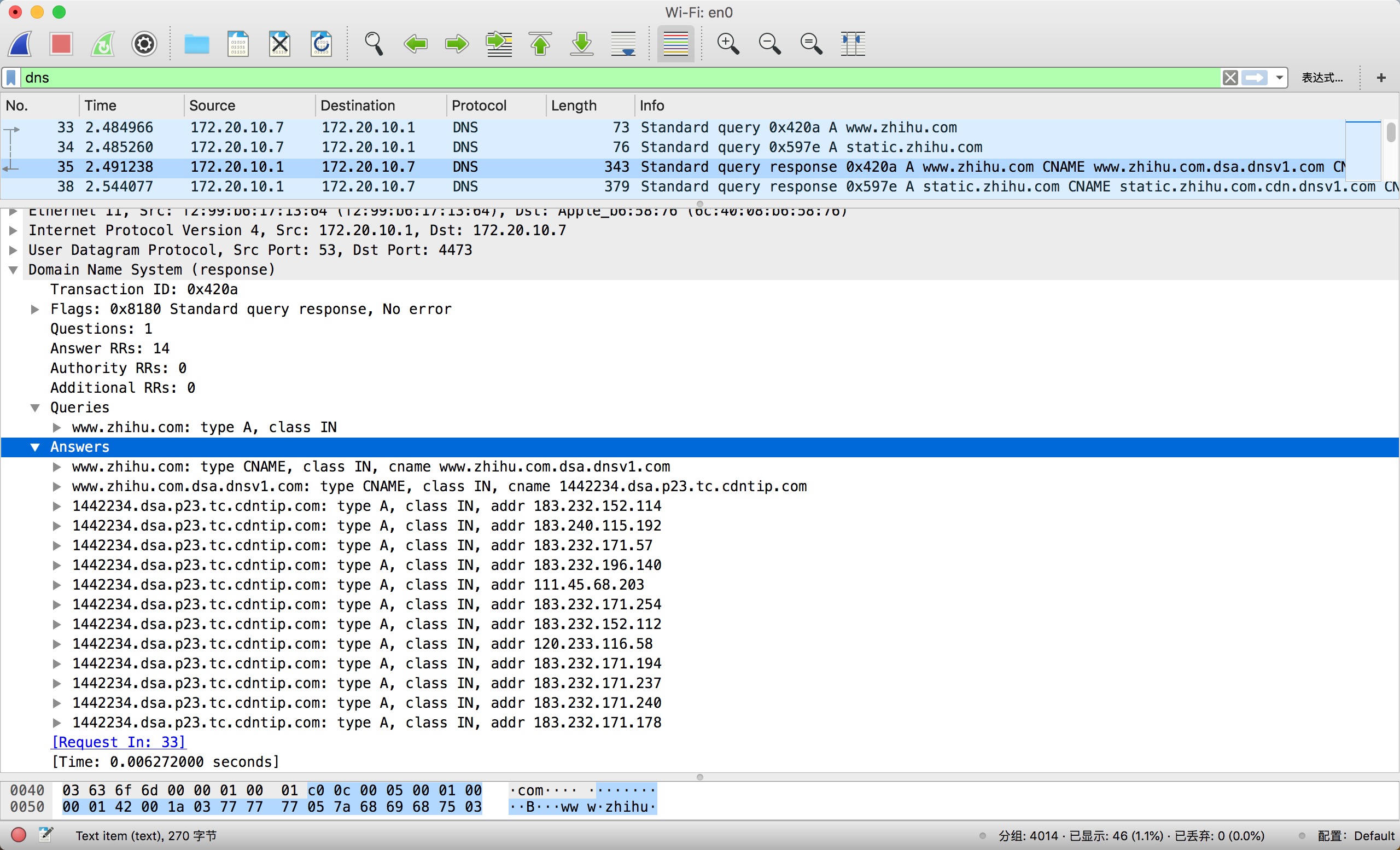
在 Answers 中有三个域名、多条记录。
- 域名 1 是
www.zhihu.com, 它设置了 CNAME,通过别名映射到了www.zhihu.com.dsa.dnsv1.com中。 - 域名 2 是
www.zhihu.com.dsa.dnsv1.com,从该域名的后缀可以得知知乎使用了腾讯云的动态加速域名(*.dsa.dnsv1.com)。知乎在腾讯云 DSA 控制台接入加速域名后,系统会为加速域名分配一个 “CNAME 域名”。随后该域名又通过 CNAME 映射到1442234.dsa.p23.tc.cdntip.com。 - (
.dsa.p23.tc.cdntip.com)。 - 域名 3 是
1442234.dsa.p23.tc.cdntip.com,该域名下配置有多个 IPv4 地址,这些 IP 地址都是腾讯云为知乎提供的加速节点。这些 IP 地址会根据接入网络不同而动态变化。
通过上面一系列的小步骤客户端得到了其中一个节点的 IP 地址,也就是 183.232.152.114。浏览器拿到 IP 地址后可以进行下一步的处理。
下面来对本地 DNS 查询做一个简单的总结:
- 浏览器发起查询请求。浏览器所在的主机作为 DNS 客户端向本地 DNS 服务器发送查询请求。
- 本地 DNS 服务器找缓存。在该步骤上找到了
www.zhihu.com的记录,于是将记录作为响应返回主机。
四、 能走到步骤四意味着在本地 DNS 服务器上也没有找到相应的记录。这时本地 DNS 服务器不会立即反馈给客户端它没货,而是将该查询转发至 ISP 提供的 DNS 服务器(缓存/转发服务器。笔者使用的是移动的网络,那就在移动的 DNS 服务器上找缓存)上查询。
下例将通过 dig 命令来查找 DNS,使用 +trace 参数指定从根名称服务器的委派路径到 www.zhihu.com 的跟踪。此例中发起查询请求的是本地 DNS 服务器(172.20.10.1),但在实际域名解析中可能是由本地 DNS 服务器发送给 ISP DNS 服务器,再由 ISP DNS 服务器去向外查找。
顺带一提,dig 命令还可以使用 @DNS服务器 指定 DNS 服务器来做进行查询解析,如指定 google 的 DNS 服务器可以添加参数 @8.8.8.8。
下面还是以默认的 DNS 服务器进行解析,dig 命令在 unix 上是读取 /etc/resolv.conf 上的配置:
1 | # 若想指定谷歌的 DNS 服务器,那就在命令行输入: |
在上面的日志可以看出,名称解析是从右向左进行解析的。
1 | now location: www.zhihu.com. |
最先查找的是根名称服务器。172.20.10.1 (本地 DNS 服务器)逐个询问根域名服务器(根名称服务器地址全球只有 13 个):“朋友,你知道 www.zhihu.com 的 IP 地址是什么?”。根名称服务器收到该询问后,若它自己不知道关于 www.zhihu.com 的相关信息,它直接告诉发起查询请求的 172.20.10.1 说它不清楚。那 172.20.10.1 就会询问下一个根名称服务器。这一个查询过程就由递归解析变为了迭代解析。
在不断的根域名迭代查询后,终于有根域名服务器知道我们想要查询域名的信息:
172.20.10.1: “朋友,你知道www.zhihu.com的 IP 地址是什么?”f.root-servers.net: “虽然我不知道具体地址映射,但你可以从COM TLD找到相关的线索。我有COM TLD的地址,你可以去问问他们”
1 | now location: www.zhihu.com. |
172.20.10.1 在跟域名服务器(f.root-servers.net)上拿到了 gTLD 服务器信息,这些服务器的名称都是像 l.gtld-servers.net.、b.gtld-servers.net. 的格式。
172.20.10.1 为了得到满足我们的需求还是得逐个拜访这些顶级域名服务器(os: 没办法,托人办事就是这样的)。询问的方式跟上面访问根域名服务器类似,直到问到了合适的人(e.gtld-servers.net)。
172.20.10.1: “朋友,你知道www.zhihu.com的 IP 地址是什么?”e.gtld-servers.net: “我这边有zhihu.com.的记录,我把它的联系方式给你,你问问它”。
1 | now location: www.zhihu.com. |
从 e.gtld-servers.net 返回了 zhihu.com. 的相关消息。但还得继续迭代查询 www.zhihu.com. 的消息,最终在 ns4.dnsv5.com 找到了我们的目标信息。
虽然 172.20.10.1 拿到了 www.zhihu.com. 的信息,但它发现这是一条 CNAME 记录,它被映射到了 www.zhihu.com.dsa.dnsv1.com. 域名上。这意味着如果 www.zhihu.com.dsa.dnsv1.com. 没有再通过 CNAME 映射到别的域名上的话,那 172.20.10.1 想要找的 IP 地址就是 www.zhihu.com.dsa.dnsv1.com. 的 IP 地址。若有再映射,就继续查找,直到找到没有再被映射的域名,最后再将该结果返回。
至于为什么会映射到 www.zhihu.com.dsa.dnsv1.com.,前文已经讲解过,此处就不再重复赘述。
1 | now location: www.zhihu.com. |
从上面的几个大步骤可以看出:从客户端与本地 DNS 服务器的查询是属于递归查询,而 ISP DNS 服务器与外部 DNS 服务器之间的查询一般都是迭代查询。
本章参考资料:
- hosts | wikipedia
- dig
- DNS Header Section Format
- 腾讯云动态加速网络
- 《TCP/IP 详解 卷一: 协议》第十一章
TCP 连接
世界上几乎所有的 HTPP 通信都是由 TCP/IP 承载的,TCP/IP 是全球计算机及网络设备都在使用的一种常用的分组交换网络分层。 HTTP 的连接实际上就是 TCP 连接以及其使用规则。 –《HTTP 权威指南》
紧接着,浏览器拿到知乎的 IP 地址(183.232.171.254) 后, 浏览器取出 URL 的端口(HTTPS 的默认端口为 443)。
随即浏览器会创建新的套接字(socket)向 183.232.171.254:443 发起 TCP 连接请求:
建立 TCP 连接时会经历三次握手:

- 首先浏览器作为客户端会发送一个小的 TCP 分组,这个分组设置了一个特殊的
SYN标记,用来表示这是一条连接请求。同时设置初始序列号为x赋值给Seq(这次捕获组的数据为: SYN=1, Seq=0)。 - 服务器接受到客户端的
SYN连接后,会选择服务器初始序号y。同时向客户端发送含有连接确认(SYN+ACK)、Seq=0(本例中的服务器初始序号)、Ack=1(客户端的序号 x + 1) 等信息的 TCP 分组。 - 客户端收到了服务器的确定字段后,向服务器发送带有
ACK=1、Seq=1(x+1)、Ack=1(服务器 Ack 信息的拷贝)等字段的 TCP 分组给服务器。
以上每一个步骤相当于是一次握手。为了确保连接双方彼此完全清除对方的状况(初始序列号等),那么三次握手缺一不可。
若在第二次握手时,服务器发送的 TCP 分组由于某些原因导致客户端没有正确的接受到,此时客户端没有接受到第二次握手的控制信息,而服务器认为已经正常连接了。这时双方对丢失数据这一情况是无法感知的,连接就无法建立。因此三次握手还是必要的。
本章扩展资料:
- 《TCP/IP 详解 卷一: 协议》
HTTPS (SSL/TSL)
建立起连接后理论上就通过 HTTP 传输数据啦。但由于 HTTP 传输数据时报文是完全透明的,因此知乎使用了 HTTPS (HTTP Secure),也就是在 TCP 与 HTTP 之间多添加一层协议做加密及认证的服务。
HTTPS 使用 SSL(Secure Socket Layer) 和 TLS(Transport Layer Security) 协议,TCP 直接与 SSL/TSL 进行通信,SSL/TSL 再与 HTTP 协议进行通信,保障了信息的安全。
HTTPS 建立通信需要一些过程,我们配通过捕获组可以看到使用 TLSv1.2 的连接过程:
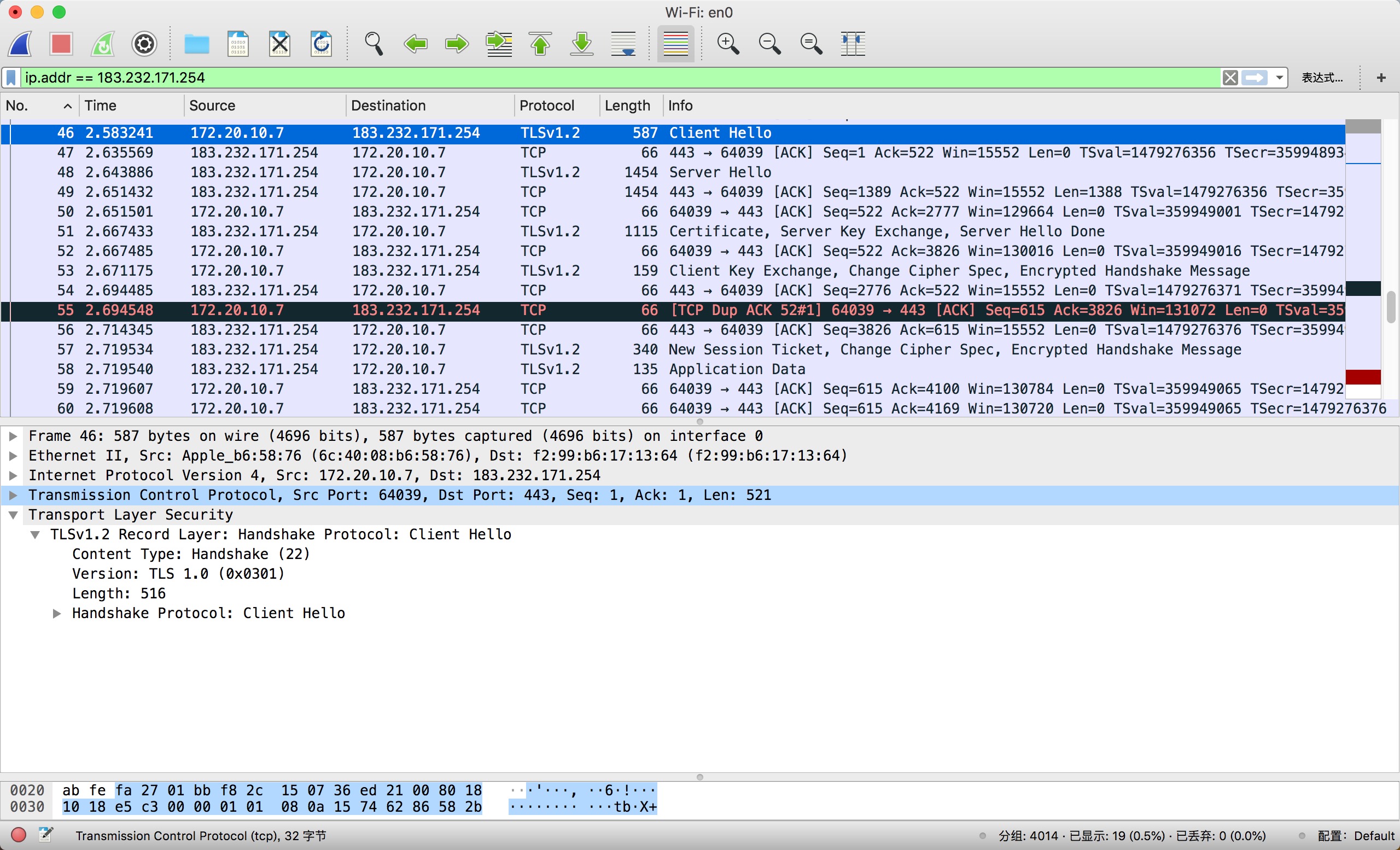
首先客户端发送
Client Hello报文开始通信,该消息包括密码套件列表以及客户端随机数。![]()
服务器接收到报文后返回
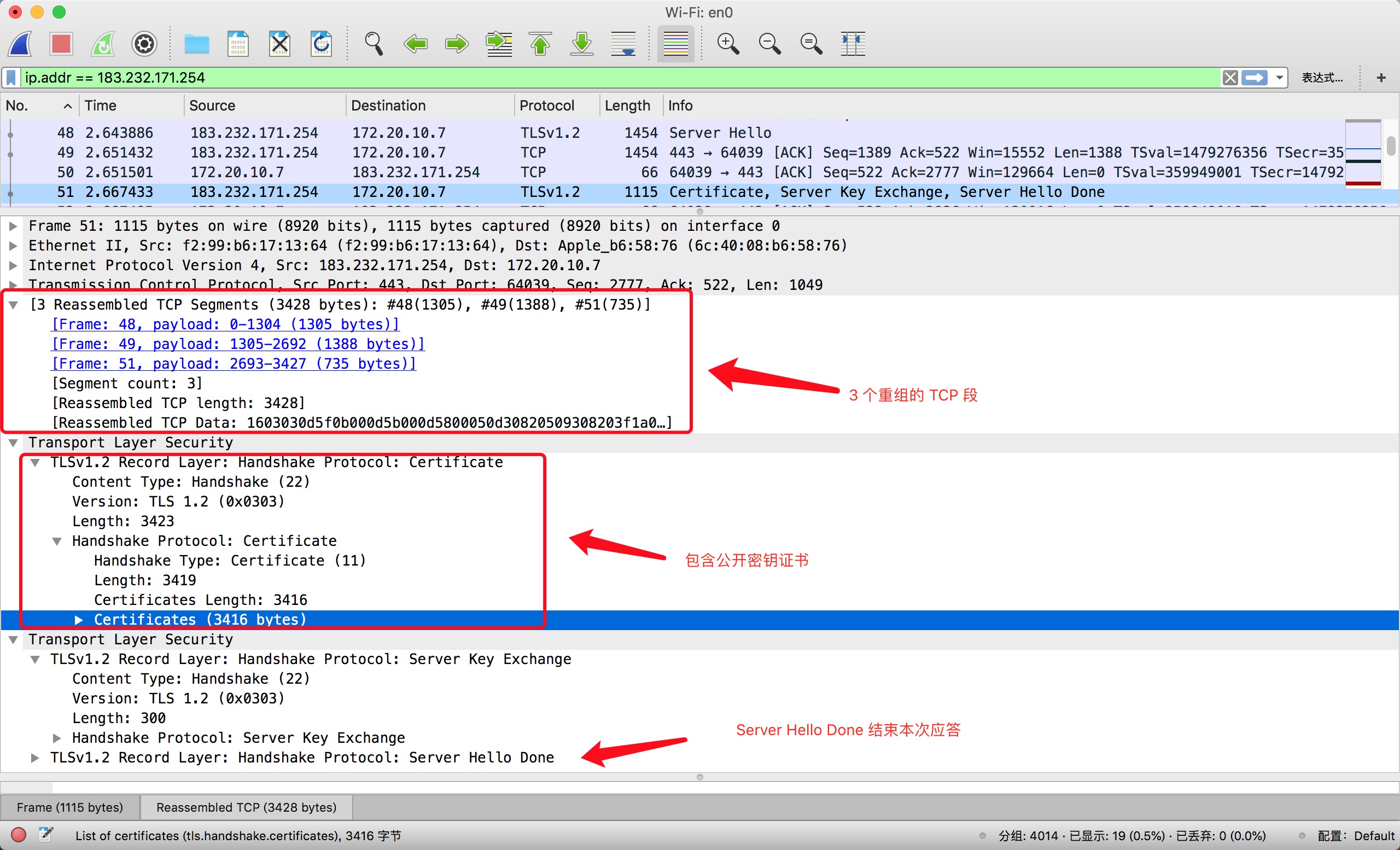
Server Hello作为应答,该消息包括其选定的密码套件和服务器随机数接着发送包含公开密匙证书的
Certificate。服务器使用
Diffie-Hellman密钥交换。获取客户端和服务器的随机数以及将用于计算会话密钥的DH参数,并使用其私钥对其进行加密,发送Server Key Exchange。服务器发送
Server Hello Done等待客户端响应。![]()
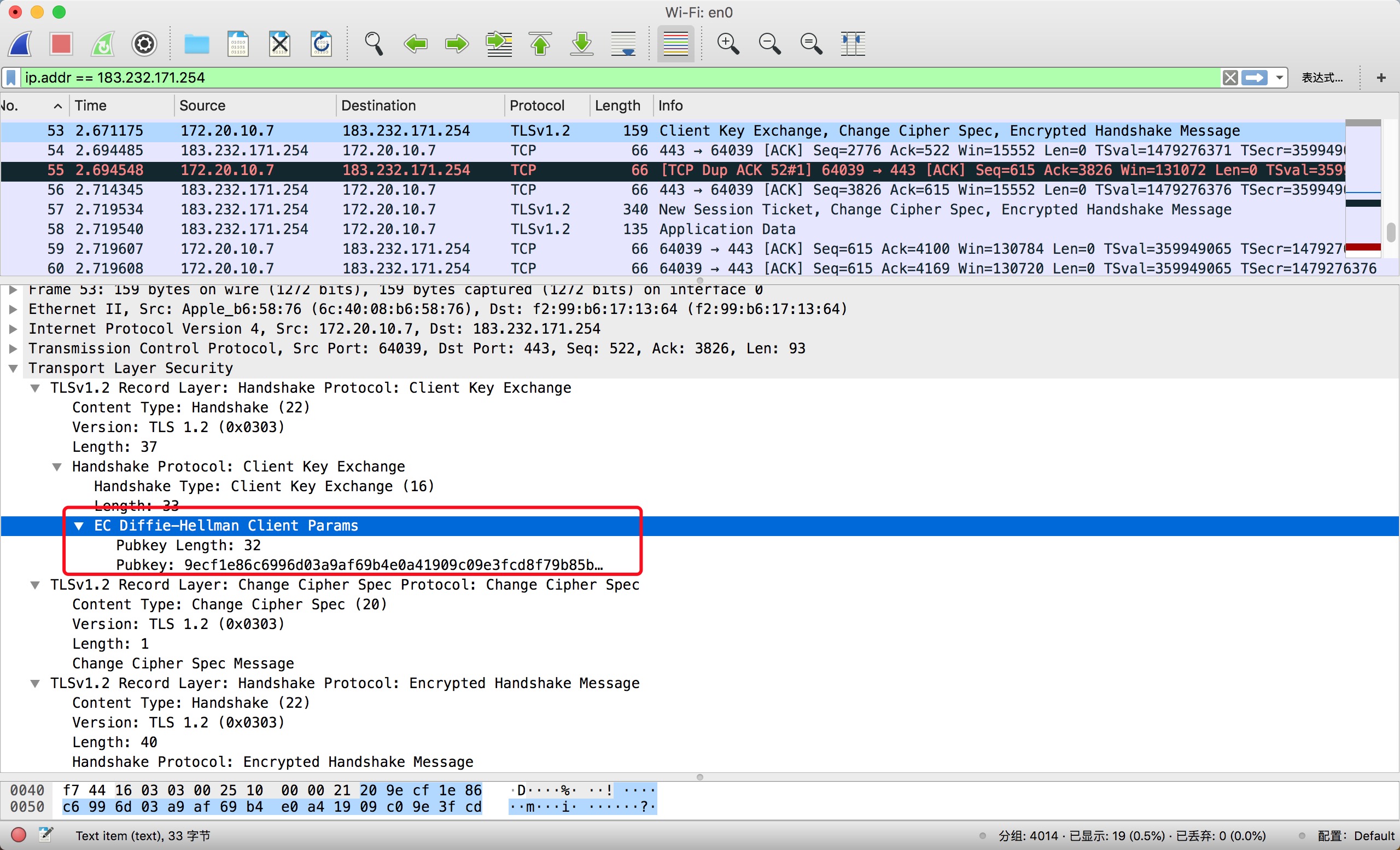
客户端使用之前交换的 DH 参数来获取
Pre-master Secret,发送Client Key Exchange。客户端发送
Change Cipher Spec指示服务器使用后续的密钥和算法加密发送后续消息。客户端使用刚刚由
DH协商出来的对称密钥加密通信报文,发送Encrypted Handshake Message(finish message),如果这个报文加解密校验成功,那么就说明对称秘钥是正确的。![]()
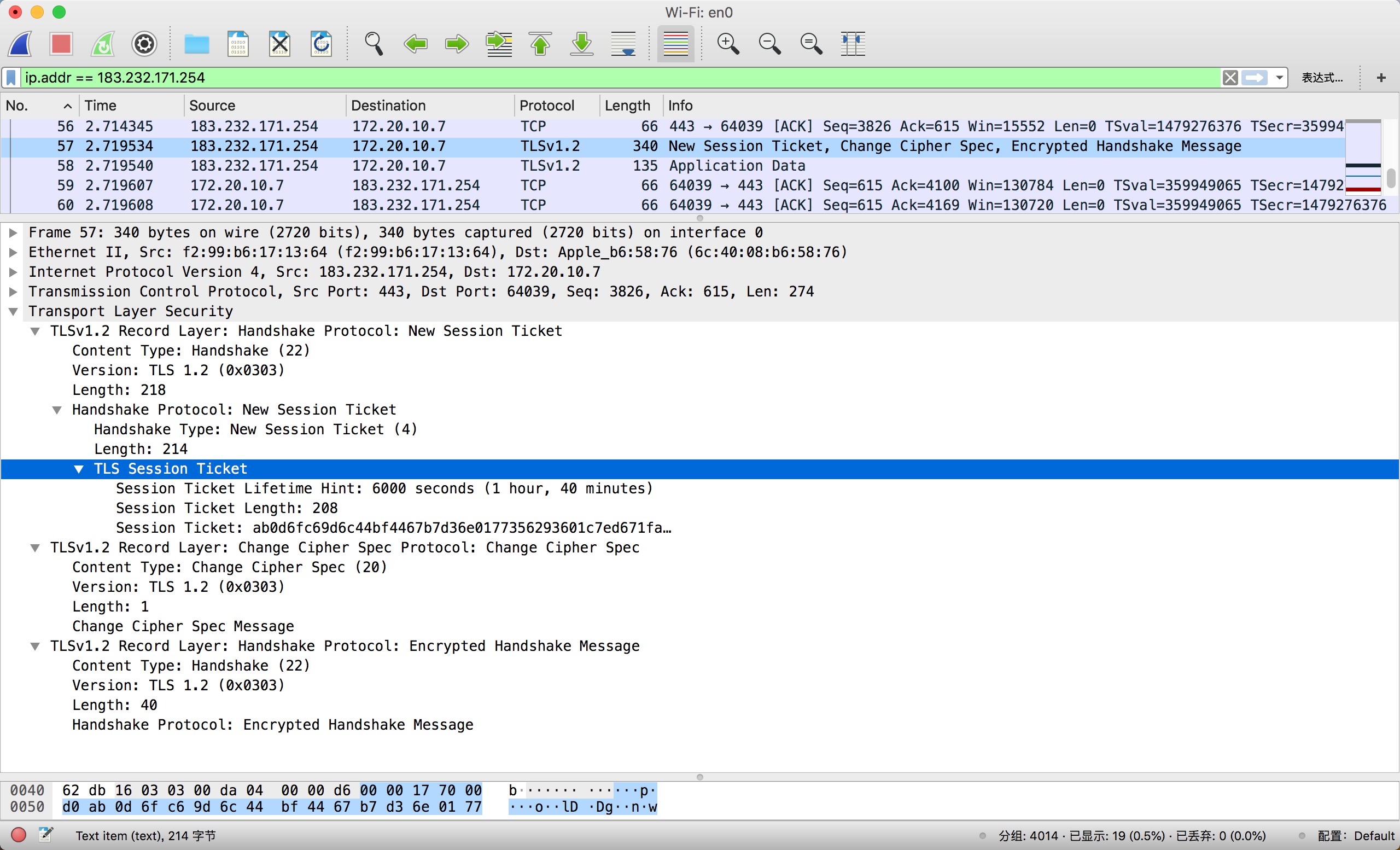
服务器验证客户端的信息后,会发送
New Session Ticket来更新客户端的session ticket。session ticket是对话密钥(session key)和加密方法经过加密后的信息,它由服务器生成,由客户端储存。服务器发送
Change Cipher Spec消息,通知客户端已更改加密规范。发送
Encrypted Handshake Message,完成服务器握手。接着就可以发送应用数据了。
本章参考资料:
- RFC 5246
- Diffie-Hellman 密钥交换
- 《图解 HTTP》
HTTP
通过 SSL/TSL 进行安全传输后,客户端发起了 HTTP GET 请求。服务器读取请求后,对 HTTP 请求进行处理。
服务器会判断请求是否合法,比如检查 cookie 信息,看用户是否有权访问这个资源。再根据请求类型做相应处理,最终会将处理结果以及 HTTP 状态码返回给客户端。
www.zhihu.com 是需要登录后才能访问的,登录过程大致如下:
- 用户在页面输入账号密码点击登录,浏览器会通过
HTTP POST提交用户信息给服务端。 - 服务端接收到用户提交的登录请求后,会验证账号密码是否正确,若正确会在 HTTP 头部通过
set-cookie设置sessionID来标识用户是否登录。下次客户端请求服务器资源时,会自动携带这些cookie信息,服务器再通过sessionID来判断请求的人是谁。注意,sessionID这字段是业界公认用于标识用户信息的字段,具体实现时也可以换一个字段名。 - 浏览器根据服务端返回的结果做相应的反应,如若登录成功,一般会通过重定向将用户带到指定的页面上。
以上是比较通用的登录流程,笔者没有去抓包来验证知乎具体的登录方案。
我们可以打开浏览器匿名模式(此时匿名模式没有 cookie 缓存),直接访问 www.zhihu.com 没有登录信息浏览器会返回 302 (临时重定向) 会被重定向 https://www.zhihu.com/signin?next=%2F 这个登录页上。


由此可以看出 HTTP 状态码与 HTTP 方法在浏览器与服务器通信之间的重要作用,下面介绍些常用的状态码与方法:
| HTTP Method(方法) | 解释 |
|---|---|
| GET | 该方法用来请求访问已被 URI 识别的资源。我们直接在浏览器地址上输入合法的 URL 后,浏览器就会发出一个 GET 请求。 |
| HEAD | 与 GET 方法类似,只不过 HEAD 只会返回头部信息,不带回资源实体。 |
| POST | 向指定资源提交数据,请求服务器进行处理。比如提交 form 表单,提交较为复杂的参数的。 |
| PUT | 向指定资源位置上传其最新内容。 |
| DELETE | 请求服务器删除指定资源。 |
| OPTIONS | 预检请求,该方法可使服务器传会资源所支持的所有请求方法。 |
HTTP 状态码可以通过首位数字区分状态码大致是属于什么类型的:
| HTTP status(状态码) | 解释 |
|---|---|
| 1xx | 消息 |
| 2xx | 成功 |
| 3xx | 除了 304 状态码,其他大多与重定向相关 |
| 4xx | 客户端错误 |
| 5xx | 服务端错误 |
日常工作中常见状态码:
| HTTP status(状态码) | 解释 |
|---|---|
| 200 (ok) | 请求成功 |
| 301 (Move Permanently) | 永久重定向,表示这资源搬家了,你去 location: //xxx.com 可以找到它 |
| 302 (Found) | 临时重定向。该资源可能临时出门旅游了,你可以先去 location: //xxx.com 看看情况。晚些时候它也可能会回来,也可能跑路了 |
| 304 (Not Modified) | 客户端发送 GET 请求时,服务器通过请求头部信息发现请求的资源跟以前请求的那份一样,没有发生改变。然后服务端会返回 304 状态码并对客户端说:你想要的资源跟以前一样,你直接用缓存的文件吧,货我就不给你,毕竟寄东西是需要邮费 |
| 400 (Bad Request) | 客户端向服务器发送的请求报文中存在语法错误,服务器看不懂就会返回 400 状态码并对客户端说: “朋友,现在我再给你一次组织语言的机会,你仔细瞧瞧是不是漏了点啥” |
| 401 (Unauthorized) | 未认证,客户端向服务器请求的资源需要认证信息,客户端没有认证信息 |
| 403 (Forbidden) | 服务器已经理解请求,但是拒绝执行它。(大灰狼: “小白兔开门,我给你叔叔的妹夫的堂兄呀!我跟你爹可是熟人”;小白兔:”大坏蛋,你休想骗我开门!“) |
| 404 (Not Found) | 请求失败,请求所希望得到的资源未被在服务器上发现。也有可能是资源存在,但服务器不想给你就假装不在。(某天你想拜访旧友,发现人家拆迁了,甚至楼都被铲平了) |
| 500 (Internal Server Error) | 服务器抛错,无法正常完成请求的处理。有可能有 bug、也可能是其他原因 |
| 503 (Service Unavailable) | 由于临时的服务器维护或者过载,服务器当前无法处理请求。这个状况是暂时的,并且将在一段时间以后恢复。访问页面遇到此错误多数情况下是正在部署页面 |
| 504 (Service Unavailable) | 作为网关或者代理工作的服务器尝试执行请求时,未能及时从上游服务器或者辅助服务器收到响应。 |
由于笔者目前的环境上没有屏幕录制工具,这里就直接用笔者以前录制的旧图来演示。下面是调整网络速度后访问掘金首页的所发起 HTTP 加载过程:

在输入网址后,浏览器向服务端发起请求,服务端会将目标资源通过 HTTP 返回,浏览器解析文档时,再一次根据文档里的(link 或者 script 标签)进一步请求外部资源(详情放在下面再说).
我们可以在Network上看到,浏览器将请求发出去后,请求的status会变为pending,这也是上面说到开始建立连接请求的第一步,正在等待服务器的回应。随即我们点进请求详情内,可以发现请求头只有少量的字段。
我们再打开一个请求状态(status)为 200 的请求,就能看到完整的请求头以及服务端传回来的响应了.
扩展资料:
- 《图解 HTTP》
- 《HTTP 权威指南》
渲染文档
浏览器开始解析页面,不同的浏览器引擎渲染过程都不太一样,这里以 webkit内核 的渲染方式为例:
首先浏览器的 HTML 解释器(HTML Parser)先工作,它将 HTML 的标签解析为 DOM 树。(DOM 树构建).
如果遇到了
<script>标签则会停止解析文档,这是因为 JavaScript 中可能会带有document.write方法,可能会重写页面的结构,因此浏览器会等待script标签下载完毕并执行后才会继续解析文档。这也是著名的 web 开发最佳实践的规则之一的由来————将
<script>放在<body/>之上,这样就不会阻塞文档解析了。接着 css 解析器(CSS Parser)会在 DOM 树构建完毕后开始解析 css,它和 DOM 树一样最后解析出来的是树形结构的CSSOM(css object module,别名也要 StyleRules),浏览器将解析后的样式信息保存到新建的
RenderStyle对象中。RenderStyle对象被RenderObject类所管理和使用.当创建 RenderObject 对象之后,每个对象是不知道自己的位置、大小等信息的,webkit 根据盒模型来计算他们的位置、大小等信息,这个过程也被称之为回流与重绘(reflow and reflow).
页面呈现.
下图是 Mozilla 官网的页面渲染的过程:

扩展阅读
后记
本篇文章是笔者去年初写的了。由于最近几个月都在研究计算机底层的知识,因此想借此机会重构本篇文章。
由于现实工作的缘故,目前只来得及对大部分内容进行重写,本篇后期一些内容讲的比较简单,如果之后还有空的话会继续重构。
本文主要是通过笔者现有的知识体系进行概括性科普,若有内容表达得不对,欢迎在评论区或私信指正~如果想更深入的学习计算机底层的知识,建议通过专业的教材进行系统的学习。本文各章下都有参考资源与推荐阅读,有兴趣的朋友可以去了解一下。
最后欢迎读者朋友们订阅笔者博客。整理学习笔记不易,不点个赞鼓励一下笔者再走吗~
- Blog RSS 笔者博客的 rss 订阅链接
- Front-End-Lab 笔者的知识碎片库

更新日志:
- 2019.12.07: 重构大纲
- 2021.05.06: 补充简短版与扩展阅读