![]()
自己收集了一套针对工作中所需的正则表达式. 多适用于字符串处理、表单验证、日志数据分析等场合,实用高效.
tips: 善用Ctrl + F输入关键字能提高查询的效率哟~
常见正则校验
表单验证
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
var userNameReg = /^[a-zA-Z0-9_-]{4,16}$/;
var reg = /^(?=.*[0-9])(?=.*[!@#$%^&*])[a-zA-Z0-9!@#$%^&*]{6,16}$/;
var mailReg = /\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*/;
var postalCode = /^\d{6}$/;
var IDCard = /(^[1-9]\d{5}(18|19|([23]\d))\d{2}((0[1-9])|(10|11|12))(([0-2][1-9])|10|20|30|31)\d{3}[0-9Xx]$)|(^[1-9]\d{5}\d{2}((0[1-9])|(10|11|12))(([0-2][1-9])|10|20|30|31)\d{2}$)/;
var IDCard_18 = /^[1-9]\d{5}(18|19|([23]\d))\d{2}((0[1-9])|(10|11|12))(([0-2][1-9])|10|20|30|31)\d{3}[0-9Xx]$/;
var numName = /^[a-zA-Z0-9]{4,16}$/;
var mate = numName.test(value.replace(/[\u4e00-\u9fa5]/g, 'aa'));
|
网络相关
1
2
3
4
5
6
7
8
9
10
11
|
var IPReg = /^(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)$/;
var pattern = /^#?([a-fA-F0-9]{6}|[a-fA-F0-9]{3})$/;
var urlReg= /^((https?|ftp|file):\/\/)?([\da-z\.-]+)\.([a-z\.]{2,6})([\/\w \.-]*)*\/?$/;
var reg = /^\w+\(({[^()]+})\)$/
|
匹配json字符串
1
2
3
4
5
6
7
8
| var ret = response.data;
if (typeof ret === 'string') {
var reg = /^\w+\(({[^()]+})\)$/
var matches = ret.match(reg);
if (matches) ret = JSON.parse(matches[1]);
}
res.json(ret);
|
联系方式
1
2
3
4
5
6
7
8
9
10
11
|
var qqReg = /^[1-9][0-9]{4,11}$/;
var qqReg = /^[a-zA-Z]([-_a-zA-Z0-9]{5,19})+$/;
var phone = /^1[3|5|8|9]\d{9}$/;
var telephone = /^(0[0-9]{2})\d{8}$|^(0[0-9]{3}(\d{7,8}))$/;
|
匹配特定数字
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
var reg = /^[1-9]\d*$/;
var reg = /^-[1-9]\d*$/;
var reg = /^-?[1-9]\d*$/;
var reg = /^[1-9]\d*|0$/;
var reg = /^-[1-9]\d*|0$/;
var reg = /^[1-9]\d*\.\d*|0\.\d*[1-9]\d*$/;
var reg = /^-([1-9]\d*\.\d*|0\.\d*[1-9]\d*)$/;
var reg = /^-?([1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0)$/;
var reg = /^[1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0$/;
var reg = /^(-([1-9]\d*\.\d*|0\.\d*[1-9]\d*))|0?\.0+|0$/;
|
字符串相关
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
var reg = /^[A-Za-z]+$/;
var reg = /^[A-Z]+$/;
var reg = /^[a-z]+$/;
var reg = /^[A-Za-z0-9]+$/;
var reg = /^\w+$/;
var reg = /\n\s*\r/;
var reg = /^\s*|\s*$/;
var rtrim = /^[\s\uFEFF\xA0]+|[\s\uFEFF\xA0]+$/g;
var reg = /[^\x00-\xff]/g;
|
匹配语系字符范围
用法:/^[\u4E00-\u9FA5]+$/(匹配简体中文)
2E80~33FFh:中日韩符号区。收容康熙字典部首、中日韩辅助部首、注音符号、日本假名、韩文音符,中日韩的符号、标点、带圈或带括符文数字、月份,以及日本的假名组合、单位、年号、月份、日期、时间等。
3400~4DFFh:中日韩认同表意文字扩充A区,总计收容6,582个中日韩汉字。
4E00~9FFFh:中日韩认同表意文字区,总计收容20,902个中日韩汉字。
A000~A4FFh:彝族文字区,收容中国南方彝族文字和字根。
AC00~D7FFh:韩文拼音组合字区,收容以韩文音符拼成的文字。
F900~FAFFh:中日韩兼容表意文字区,总计收容302个中日韩汉字。
FB00~FFFDh:文字表现形式区,收容组合拉丁文字、希伯来文、阿拉伯文、中日韩直式标点、小符号、半角符号、全角符号等。
正则函数使用示例
replace
1
2
3
4
|
function getLen(str) {
return str.replace(/[^\x00-\xff]/g, 'xx').length;
}
|
test
1
2
3
4
5
6
7
8
9
|
var reg = /\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*/;
var mail = reg.test('anran758@gmail.com')
if (mail) {
}
|
正则技巧
反向引用
1
2
3
4
|
'2018-3-21'.replace(/(\d{4})-(\d{1,2})-(\d{1,2})/g, '$2/$3/$1')
|
忽略分組
不希望捕获某些分组, 只需要分组内加上?:即可:
1
2
| var reg = /(?:Byron).(ok)/;
'Byron-ok'.replace(reg, '$1');
|
前瞻
| 名字 | 正則 |
|---|
| 正向前瞻 | exp(?=assert) |
| 负向前瞻 | exp(?!assert) |
正向前瞻就是匹配前者, 效验后者是否存在.
1
2
3
4
5
6
7
|
'a2*3'.replace(/\w(?=\d)/g, 'X')
'a2*34v8'.replace(/\w(?=\d)/g, 'X')
|
负向前瞻则相反, 匹配前面, 替代后面
1
2
3
4
5
6
7
8
9
|
'a2*34v8'.replace(/\w(?!\d)/g, 'X')
|
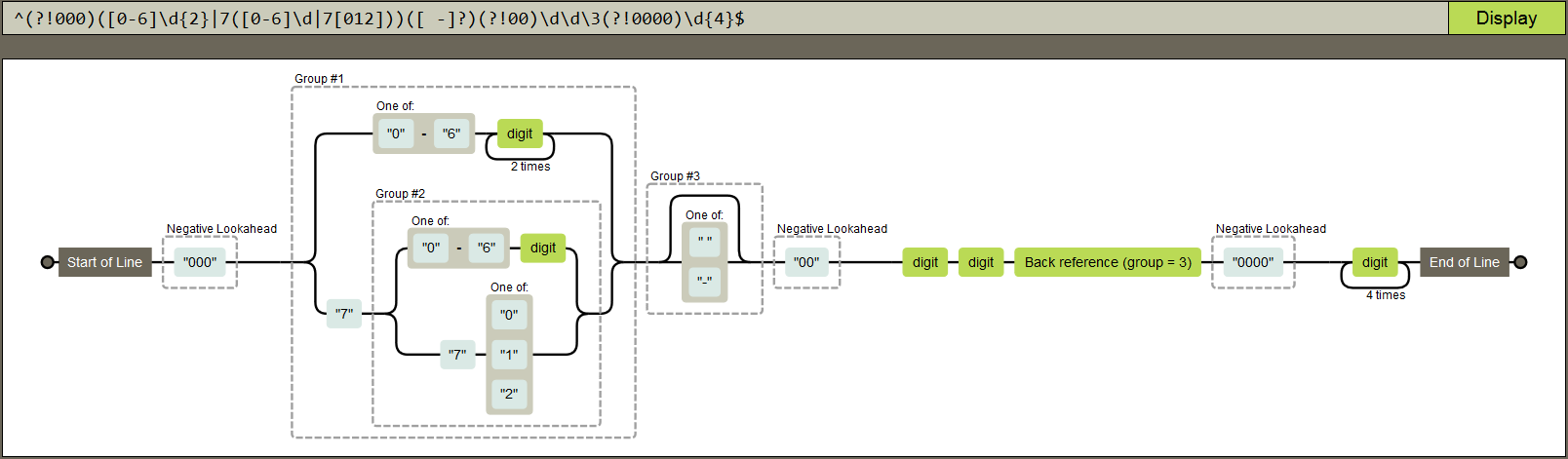
可视化正则表达式, 可以试试regexper, 让你看懂正则匹配的走向.
![]()
以后的更新与维护都将在 Front-End-Lab/REGEXP 中。